LLM Course With Slides
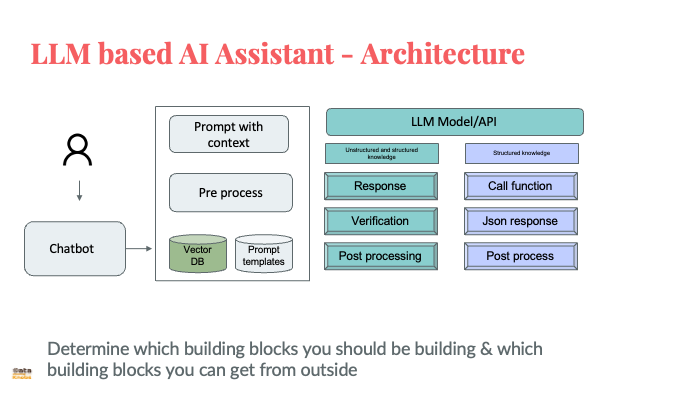
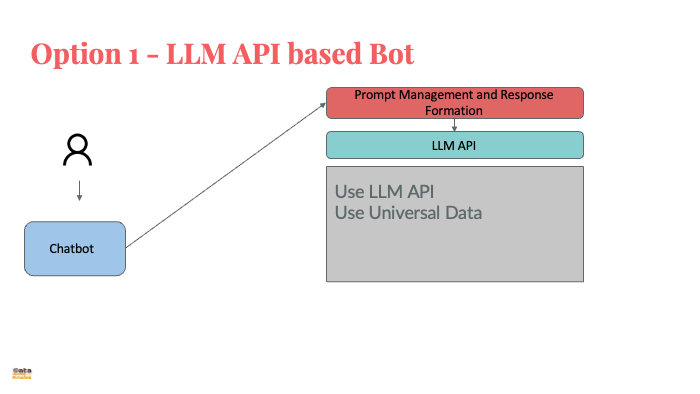
LLM 101 - This slide session walk thru LLM applications, architecture and building blocks. Slides describe open source vs closed LLM and how to choose. Slides also focus on LLM steerability. Session slides also describe prompt engineering , tokenization and factors to consider while building applications using LLM. At last it describe process architectur, component architecture and how to estimate cost of LLM.








































Large Language Models (LLMs)
LLMs are a type of artificial intelligence (AI) capable of processing and generating human-like text in response to a wide range of prompts and questions. Trained on massive datasets of text and code, they can perform various tasks such as:
Generating different creative text formats: poems, code, scripts, musical pieces, emails, letters, etc.
Answering open ended, challenging, or strange questions in an informative way: drawing on their internal knowledge and understanding of the world.
Translating languages: seamlessly converting text from one language to another.
Writing different kinds of creative content: stories, poems, scripts, musical pieces, etc., often indistinguishable from human-written content.
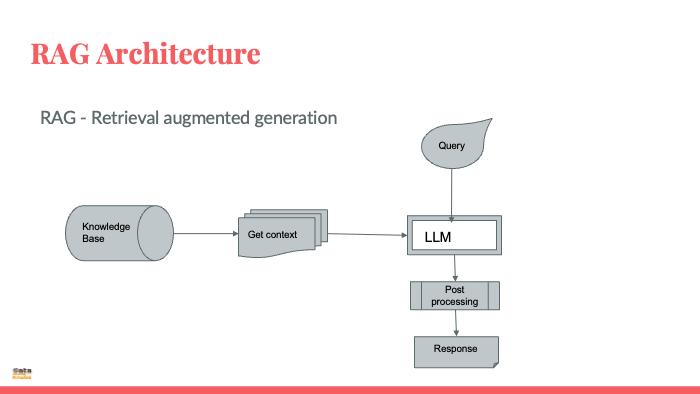
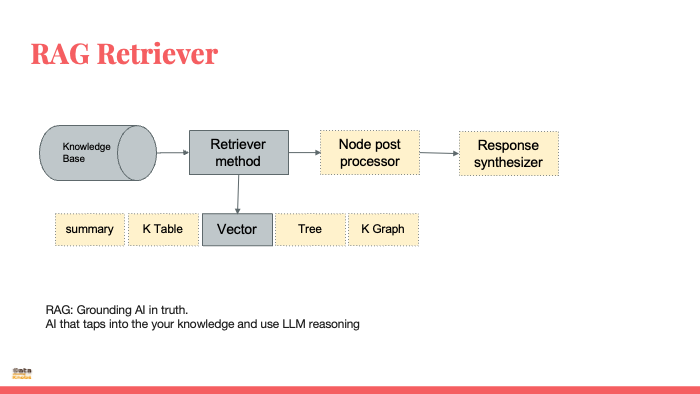
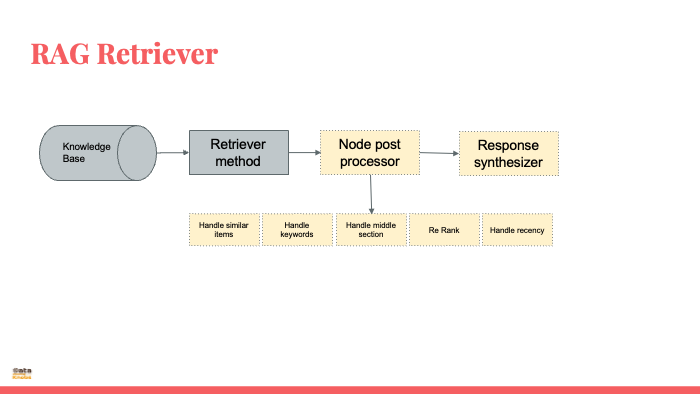
Retrieval Augmented Generation (RAG)
RAG is a novel approach that combines the strengths of LLMs with external knowledge sources. It works by:
Retrieval: When given a prompt, RAG searches through an external database of relevant documents to find information related to the query.
Augmentation: The retrieved information is then used to enrich the context provided to the LLM. This can be done by incorporating facts, examples, or arguments into the prompt.
Generation: Finally, the LLM uses the enhanced context to generate a response that is grounded in factual information and tailored to the specific query.
RAG offers several advantages over traditional LLM approaches:
Improved factual accuracy: By anchoring responses in real-world data, RAG reduces the risk of generating false or misleading information.
Greater adaptability: As external knowledge sources are updated, RAG can access the latest information, making it more adaptable to changing circumstances.
Transparency: RAG facilitates a clear understanding of the sources used to generate responses, fostering trust and accountability.
However, RAG also has its challenges:
Data quality: The accuracy and relevance of RAG's outputs depend heavily on the quality of the external knowledge sources.
Retrieval efficiency: Finding the most relevant information from a large database can be computationally expensive.
Integration complexity: Combining two different systems (retrieval and generation) introduces additional complexity in terms of design and implementation.
Prompt Engineering
Prompt engineering is a crucial technique for guiding LLMs towards generating desired outputs. It involves crafting prompts that:
Clearly define the task: Specify what the LLM should do with the provided information.
Provide context: Give the LLM enough background knowledge to understand the prompt and generate an appropriate response.
Use appropriate language: Frame the prompt in a way that aligns with the LLM's capabilities and training data.
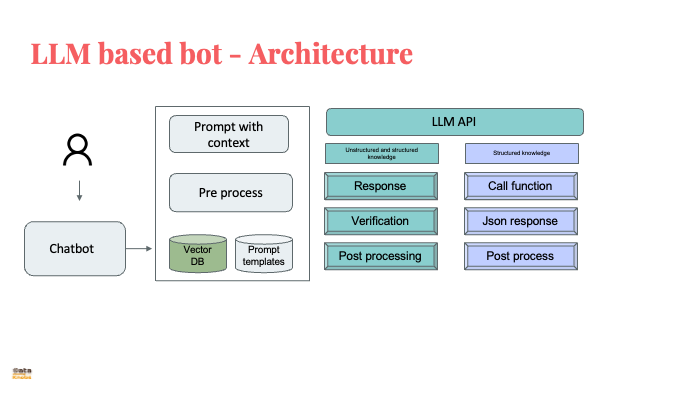
Advantage of using RAGBetter Accuracy: If factual correctness is crucial, RAG can be fantastic. It retrieves information from external sources, allowing the AI assistant to double-check its responses and provide well-sourced answers. Domain Knowledge: Imagine an AI assistant for medical diagnosis or legal or up to date tax laws. RAG can access medical databases to enhance its responses and ensure they align with established medical knowledge. Reduce Hallucination: LLMs can sometimes fabricate information, a phenomenon called hallucination in which they make up things. RAG mitigates this risk by grounding the response in retrieved data. Building Trust: By citing sources, RAG fosters trust with users. Users can verify the information and see the reasoning behind the response. Disadvantages of using RAGSpeed is Crucial: RAG involves retrieving information, which can add a slight delay to the response. If real-time response is essential, a pre-trained LLM might be sufficient. Limited Context: RAG works best when the user's query and context are clear. If the conversation is ambiguous, retrieved information might not be relevant. Privacy Concerns: If the AI assistant deals with sensitive user data, RAG might raise privacy concerns. External retrievals could potentially expose user information. |
||||||||||||
|
|
||||||||||||
When to finetune LLM |
||||||||||||
|
Consider fine-tuning a large language model (LLM) when you want it to perform better at a specific task or adapt to a particular domain. Here are exampple scenarios where fine-tuning is optimal
Domain-Specific Nuances: If you need an LLM for financial analysis, legal document or on medical document - finething is better. Example word capital has meaning in finance domain. While a pre-trained LLM might understand language, it won't grasp legal, finance or medical specific terms or jargons. Fine-tuning on finance Q&A, document or legal documents will imrpove the LLM to that specific domain. Instruction Fine-Tuning: This is a recent advancement where you provide the LLM with instructions or demonstrations alongside training data. This can be useful for tasks where you want the LLM to follow a certain style or format, like writing safety instructions in a specific tone. Specialized Tasks: Imagine you want an LLM to write different kinds of creative content, like poems or code. Fine-tuning on a dataset of poems can improve its poetry generation skills, while fine-tuning on code samples can enhance its code writing abilities. However, fine-tuning isn't always the right answer. Here are examples when you should not do fine tuning. In fact you should first use standard LLM, prompt engineering. Then try RAG. Later consider fine tuning. General Use Cases: If you need a broad LLM for various tasks, a pre-trained model will do better job. Pre-trained models are versatile, trained on diverse data and can handle many tasks well enough without specific fine-tuning. Limited Data: Fine-tuning works well when you have lot of data related to your specific task or domain. If you only add few records which most demo shows - fine-tuning might not be effective and could even harm the model's performance. Knowledge Integration: If your goal is to add propietary/latest/specific knowledge to the LLM, retrieval-augmented-generation (RAG)is better approach. In RAG LLM retrieves relevant information from a knowledge base. You can use out of box RAG. You can further optimize it by smmarizing knowledge,, creating embeddings with meta data etc. |
||||||||||||
|
|
||||||||||||
Fine Tuning Steps |
||||||||||||
|
How can LLMs be fine-tuned for summarization? LLMs (Large Language Models) like GPT-3 can be fine-tuned for summarization using the following approaches: Supervised training - The simplest approach is to fine-tune the LLM using a large dataset of text-summary pairs. The model is trained to generate the corresponding summary given the input text. This requires a sizable supervised dataset, which can be expensive to create. Public datasets like CNN/DailyMail can be used. Self-supervised training - The LLM is trained using the original text as input and the first few sentences as the "summary". This creates weak supervision from the data itself. The model is then fine-tuned on a smaller set of human-written summaries to improve accuracy. This approach requires less labeled data. Reinforcement learning - The LLM is first trained autoencoding - to reproduce the input text. Then, rewards are given based on the quality and conciseness of the generated summary. The model learns to generate better summaries through trial-and-error to maximize these rewards. However, this requires defining a good reward function. Filtering and post-processing - Generated summaries from the LLM can be filtered and refined using techniques like: • Extracting sentences with the highest similarity to human references • Removing repetitive sentences • Combining overlapping content into a single sentence, etc. This requires minimal fine-tuning of the base LLM but provides less control over the summary style. Prompting - The LLM can be "prompted" to generate a summary using natural language instructions. For example: In 2-3 short paragraphs, summarize the main points of the following text: This relies more on the pre-trained LLM abilities and requires less labeled data. But accuracy tends to be lower. So in short, there are a variety of approaches to fine-tune LLMs for summarization - from fully supervised to minimally supervised. The choice depends on the available data, required accuracy and custom need. |
||||||||||||
|
|
||||||||||||
Verify LLM and AI Assistant Answers |
||||||||||||
|
If you are using AI Assistant, you should cross check facts/number given by AI Assistant
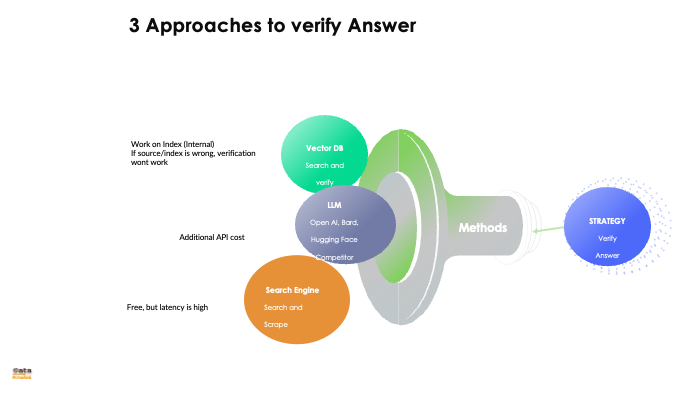
Check in Vecor DB: If you are using Vector DB/RAG, you can check what value RAG provide. This will help to ensure that response generated by RAG is in line with value stored in vector DB. Use Second LLM: Other/aditional approach is you can ask a smaller question from second or same LLM and se what answer you get e.g. if there is 1 page of text and it says company Dataknobs has revenue of $78M, you can ask a smaller question "how much revneue Dataknobs has". However you need to consider additional cost of 2nd call? You may have more than one fact and multiple calls may be needed for each fact. Call to Search Engine: You can run a query on search engine programmatically and chec response. However depending on domain this result may or may not work. It may require parsing result from search engine. |
||||||||||||
|
|
||||||||||||
|
|
||||||||||||
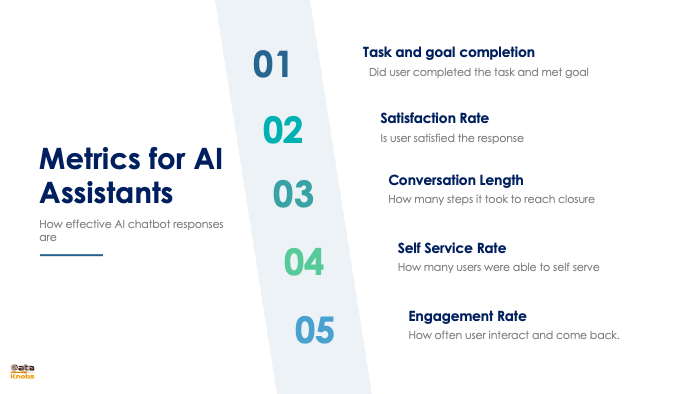
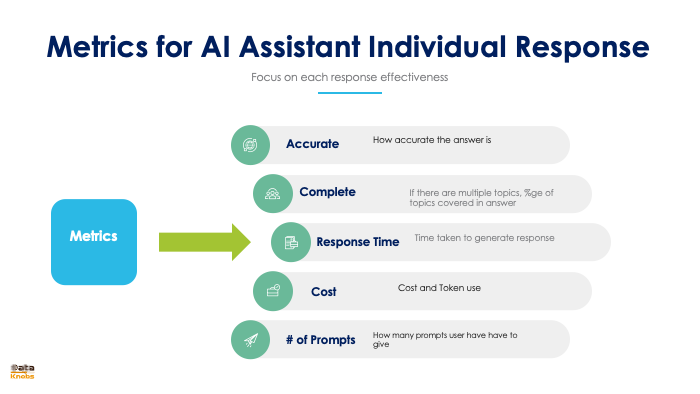
How to evaluate LLM |
||||||||||||
|
||||||||||||
|
|
||||||||||||