Explore All Topics
 01 / Overview
01 / Overview
Vector Databases Overview: Introduction, Traditional DB Comparison, Selection Criteria & Vendor Landscape
Vector databases have emerged as a cornerstone of the modern AI stack purpose-built to store, index, and search high-dimensional embeddings generated by deep learning models. This overview maps the full landscape: how vector DBs differ from relational, document, and search databases; which vendors are leading the market; and the key criteria for matching a platform to your workload and scale requirements.
- Vector DBs optimise for approximate nearest-neighbour (ANN) search over embedding spaces
- Traditional databases lack native support for high-dimensional vector operations at scale
- Selection dimensions include performance, scalability, cloud vs. on-prem, and open-source vs. managed
- Market leaders include Pinecone, Weaviate, Milvus/Zilliz, Chroma, Faiss, and LanceDB
 02 / What Are They
02 / What Are They
What Are Vector Databases: Storing Embeddings & Enabling Similarity Search for Unstructured Data
A vector database is a specialised data store that indexes and retrieves items based on mathematical similarity rather than exact key or keyword matches. ML models convert raw content text, images, audio, code into dense numerical vectors (embeddings), and the vector DB enables lightning-fast retrieval of the most semantically similar items from billions of candidates.
- Embeddings are dense float arrays (e.g. 768 or 1536 dimensions) produced by neural encoders
- ANN algorithms HNSW, IVF, ScaNN trade tiny accuracy loss for 100–1000× speed gains
- Metadata filtering allows hybrid search: combine vector similarity with structured attributes
- Unstructured data (images, docs, audio) becomes queryable without manual feature engineering
 03 / Use Cases
03 / Use Cases
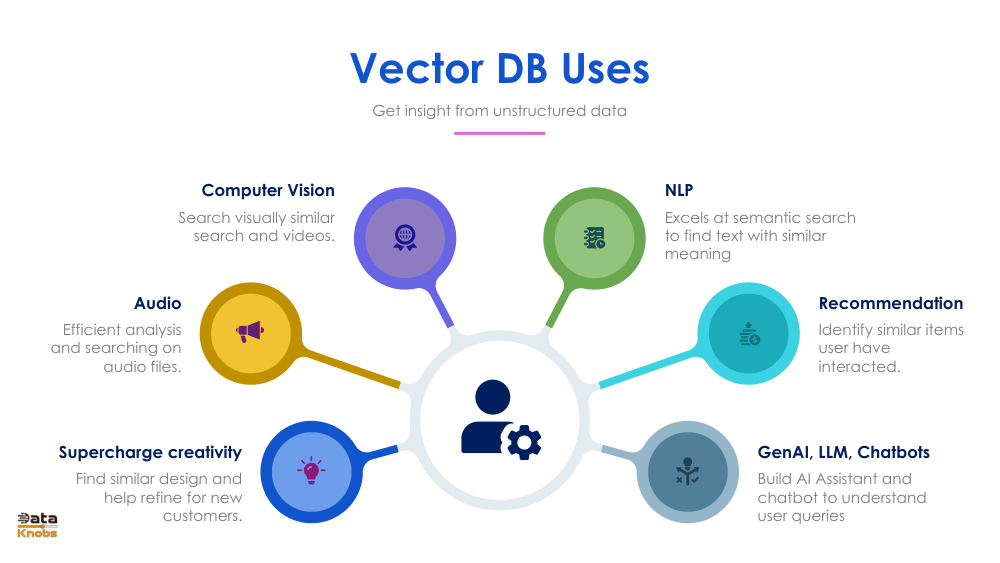
Vector Database Use Cases: Computer Vision, NLP, Recommendations, Chatbots, Audio & Search
Vector databases are the hidden infrastructure behind many of the most impactful AI applications today from image reverse-search to LLM-powered chatbots. Their ability to retrieve semantically similar content across any modality makes them universally applicable wherever "find the most relevant item" is the core operation.
- Semantic search: retrieve documents by meaning, not just keyword overlap critical for enterprise Q&A
- RAG pipelines: inject fresh context into LLM prompts without re-training the model
- Recommendation engines: surface similar products, articles, or songs based on user embedding history
- Computer vision: reverse image search, face recognition, and visual product discovery at scale
 04 / vs Traditional DBs
04 / vs Traditional DBs
Vector DBs vs Traditional Databases: Differences in Storage, Search & Handling High-Dimensional Data
Relational databases excel at structured queries; vector databases excel at semantic retrieval. The two systems use fundamentally different index structures B-trees for exact lookups versus graph-based HNSW or cluster-based IVF for approximate nearest-neighbour search leading to radically different performance profiles for AI workloads.
- SQL/NoSQL: optimised for exact match, range queries, and structured schema not similarity
- Vector DBs store embedding vectors alongside metadata; queries return ranked neighbours by distance
- The "curse of dimensionality" makes traditional indexing exponentially slower above ~20 dimensions
- Hybrid deployments combine a relational DB (source of truth) with a vector DB (semantic retrieval)
 05 / Vendors
05 / Vendors
Vector Database Vendors: Pinecone, Milvus, Weaviate, Faiss, Zilliz, Chroma DB & LanceDB Compared
The vector database market has exploded from a niche research tool to a vibrant ecosystem of specialised platforms in under three years. Each vendor makes distinct trade-offs across performance, ease of use, open-source availability, cloud integration, and enterprise features making the right choice highly workload-dependent.
- Pinecone: fully managed, serverless, easiest onboarding best for teams prioritising speed-to-production
- Milvus/Zilliz: open-source powerhouse with the most indexing algorithms and enterprise-scale performance
- Weaviate: built-in ML model integrations and GraphQL API strong for hybrid semantic + structured search
- Chroma & LanceDB: lightweight, developer-friendly options ideal for local development and RAG prototyping
 06 / Feature Comparison
06 / Feature Comparison
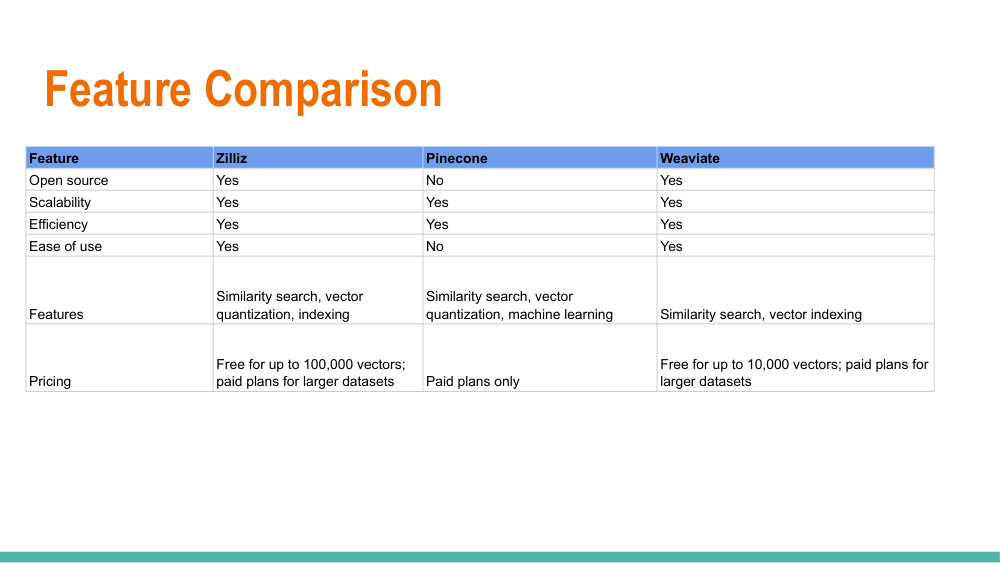
Vector Database Feature Comparison: Zilliz, Pinecone & Weaviate Source, Efficiency & Pricing
A side-by-side feature matrix of the three most enterprise-adopted vector databases Zilliz (cloud-managed Milvus), Pinecone, and Weaviate covering open-source licensing, indexing efficiency, filtering capabilities, multi-tenancy, observability, and total cost of ownership at different scales.
- Zilliz: open-core (Apache 2.0), highest indexing throughput, best suited for self-hosted + cloud hybrid
- Pinecone: proprietary, zero-ops managed service, pod-based or serverless pricing model
- Weaviate: open-source (BSD), built-in vectorisation modules, strong GraphQL + REST API
- Pricing varies dramatically: serverless Pinecone vs. Weaviate Cloud vs. self-hosted Zilliz/Milvus
 07 / What Are Vectors
07 / What Are Vectors
What Are Vectors: Mathematical Representation, High-Dimensional Space & Similarity Search Foundations
Before you can work with vector databases, you need to understand what vectors are and how distance metrics encode semantic meaning. A vector is an ordered list of floats representing a point in n-dimensional space and the mathematical distance between two points encodes how semantically related two pieces of content are.
- Cosine similarity measures the angle between vectors independent of magnitude, ideal for text
- Euclidean (L2) distance measures straight-line distance preferred for image and audio embeddings
- Dot product similarity is fastest to compute and used in maximum inner-product search (MIPS)
- Dimensionality reduction (PCA, UMAP) helps visualise and compress high-dimensional embedding spaces
 08 / Selection Criteria
08 / Selection Criteria
Criteria to Select a Vector Database: Scalability, Performance, Deployment, Security & Ecosystem
Choosing the wrong vector database can mean costly migrations later. This evaluation framework covers the five critical dimensions performance benchmarks, deployment model, scalability ceiling, security posture, and ecosystem integrations that should drive your selection process before writing a single line of code.
- Performance: measure QPS, recall@K, and p99 latency on your actual embedding dimensions and dataset size
- Deployment: fully managed SaaS vs. self-hosted open-source vs. hybrid each has different TCO implications
- Scalability: evaluate horizontal sharding, replication, and multi-tenancy support for future growth
- Ecosystem: LangChain, LlamaIndex, and cloud provider integrations reduce integration effort significantly
 09 / vs Elasticsearch
09 / vs Elasticsearch
Vector Databases vs Elasticsearch: Core Focus, Data Model & Performance Differences for Search Workloads
Elasticsearch pioneered full-text search with its inverted index and BM25 ranking but adding dense vector search as a bolt-on is fundamentally different from a ground-up vector-native architecture. This comparison helps teams understand when Elastic's kNN plugin suffices and when a dedicated vector DB is the right choice.
- Elasticsearch excels at keyword/BM25 search, faceting, and log analytics mature and battle-tested
- Vector-native DBs out-perform Elastic's kNN on ANN recall, throughput, and memory efficiency
- Hybrid search (BM25 + vector) is possible in both but implementation complexity differs significantly
- For pure semantic search at scale, dedicated vector DBs offer 3–5× better price/performance
 10 / Dimensions
10 / Dimensions
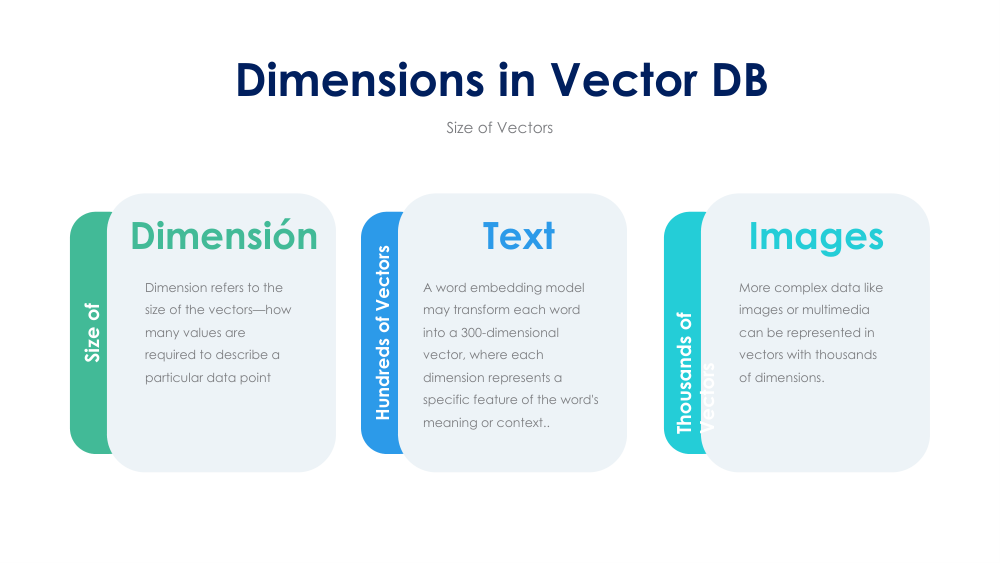
Dimensions in Vector Databases: Using Vectors for Text, Images & Multimodal Similarity Search
Dimensionality is the number of floats in each embedding vector, and it directly drives storage cost, memory footprint, and query latency. Understanding what different model families produce and how to choose between 384-dim sentence transformers and 3072-dim OpenAI embeddings is essential for cost-effective vector database design.
- Text: sentence-transformers range from 384 to 1024 dims; OpenAI text-embedding-3-large = 3072 dims
- Images: CLIP embeddings at 512 dims enable cross-modal text-to-image and image-to-image search
- Multimodal models unify text, image, and audio into a shared embedding space for unified retrieval
- Higher dimensions = richer semantics but proportionally higher storage and memory costs
 11 / CRUD Operations
11 / CRUD Operations
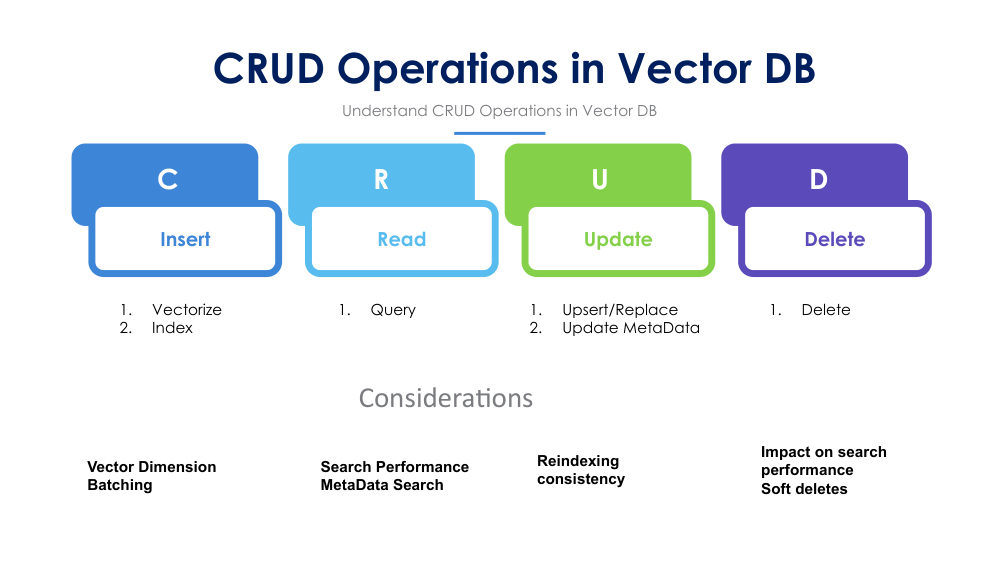
CRUD Operations in Vector Databases: Create, Read, Update & Delete with Indexing Considerations
Vector databases support the same four fundamental operations as any database but each operation has unique implications for index integrity and query performance. Understanding how inserts trigger re-indexing, how updates are handled (copy-on-write vs. in-place), and how deletes affect ANN graph structures is critical for production system design.
- Insert (upsert): vectors are added to the index batch inserts are 10–100× more efficient than row-by-row
- Query (search): ANN search returns top-K neighbours by distance; combine with metadata filters for precision
- Update: most vector DBs implement update as delete + re-insert, triggering partial index rebuild
- Delete: soft-delete (tombstoning) is common to avoid expensive graph restructuring in HNSW
 12 / Update Challenges
12 / Update Challenges
Challenges of Frequent Updates in Vector Databases: Indexing, Storage Overhead, Performance, Consistency & Cost
Vector databases are optimised for write-once, read-many workloads. High-frequency updates introduce compounding challenges: HNSW graph degradation reduces recall, soft-deleted tombstones inflate storage, and segment compaction causes latency spikes. This topic covers mitigation strategies for real-time vector workloads.
- Index degradation: frequent deletes fragment the HNSW graph, progressively reducing ANN recall accuracy
- Storage overhead: tombstoned vectors persist until compaction can double storage footprint in busy systems
- Segment compaction: background merge operations compete for I/O and cause unpredictable latency spikes
- Mitigation: scheduled index rebuilds, streaming segment compaction, and DiskANN for update-heavy workloads
 13 / Industry Applications
13 / Industry Applications
Vector Database Applications Across Industries: E-commerce, Healthcare, Finance, Media, Manufacturing & Publishing
Every industry that works with unstructured data which is virtually all of them has compelling vector database applications. From drug discovery in pharma to fraud detection in fintech to personalised content in media, semantic search and embedding-based retrieval are unlocking value that structured databases simply cannot deliver.
- E-commerce: visual product search, personalised recommendations, and multi-lingual catalogue search
- Healthcare: similar-patient matching, medical imaging retrieval, and drug-compound similarity search
- Finance: fraud pattern detection, document similarity for contract review, and news-driven signal retrieval
- Media & publishing: content deduplication, personalised feeds, and cross-lingual article matching